图计算
简介
图计算是一种处理和分析大规模图数据结构的技术。随着社交网络、知识图谱、推荐系统等应用的兴起,图计算技术已经成为数据处理领域的一个热点。 ArcGraph 涵盖了图计算的存储、处理和通信等关键领域,为用户提供一个高效、可扩展和灵活的图计算平台,ArcGraph 图计算架构图如下所示。
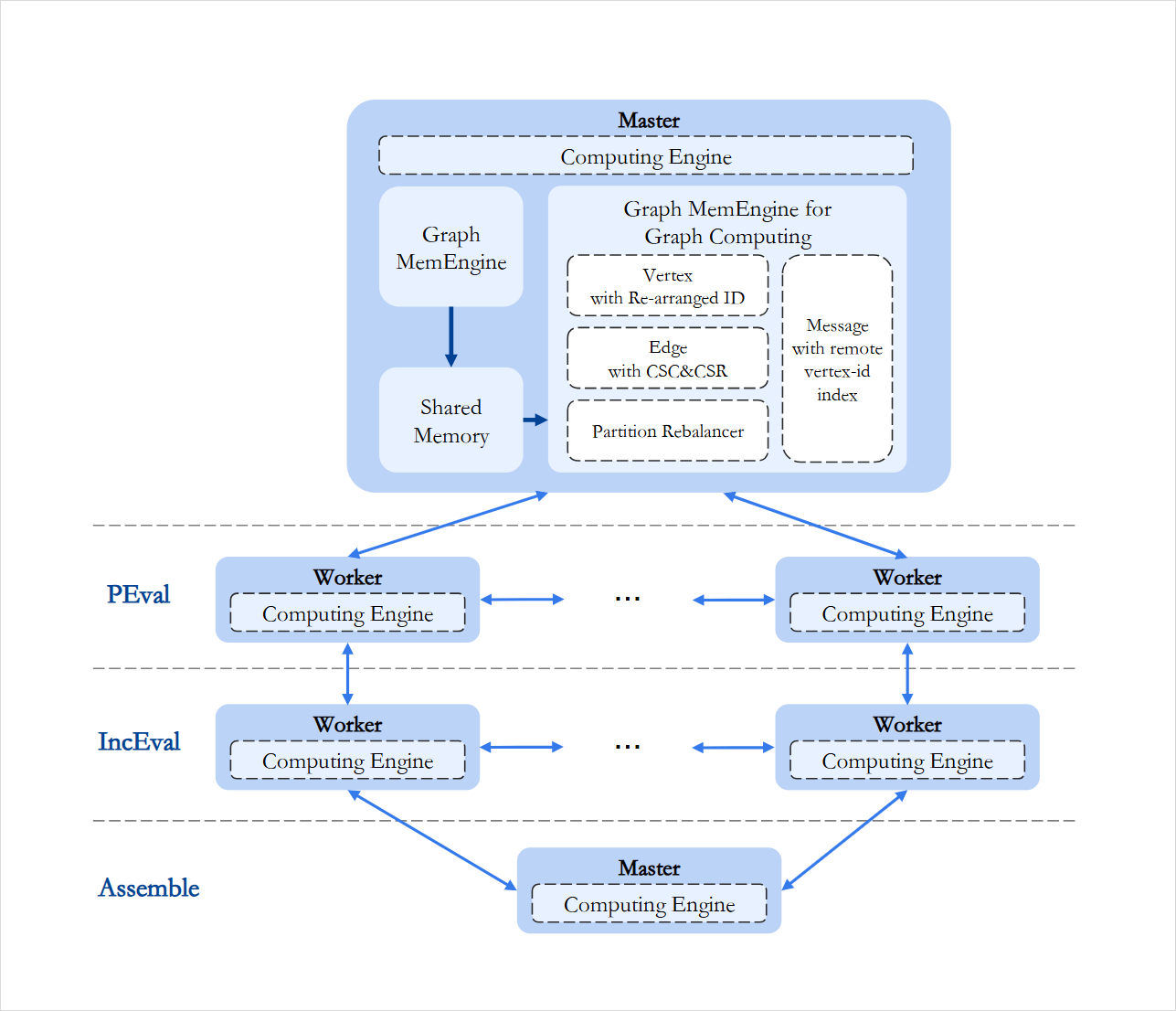
主要优势
-
高性能图计算内存引擎
- 向量化计算效率提升:向量化计算利用单指令多数据(SIMD)指令集,可以同时处理多个数据项,大大提高了计算效率。在图计算中,这意味着可以更快地处理图的节点和边。
- 边数据读取性能优化:图的边数据通常非常庞大。优化边数据的读取性能可以大幅提��高整体的计算速度,特别是当从磁盘或网络读取数据时。
- 支持更高效的PIE计算模型,兼容 Pregel:PIE(Partitial-Incremental-assEmbal)是一个新的图计算模型,它旨在提高图计算的效率。而Pregel是Google推出的一个大规模图处理框架。一个良好的图计算引擎应该同时支持这两种模型,以满足不同应用的需求。
- 平衡分区数据分布:在分布式图计算中,数据分布的均衡性对于确保所有计算节点均衡负载和最大化资源利用至关重要。
-
高性能网络通信框架
- 优化序列化/反序列化性能,降低数据传输量:序列化是将数据结构或对象转换为字节流的过程,以便在网络上发送或存储。优化序列化和反序列化的性能可以减少数据传输和处理的时间。
- 实现Pull与Push机制,同时支持稀疏图与稠密图:Pull和Push是两种不同的数据通信机制。在Pull模式下,计算节点从其他节点请求数据;在Push模式下,计算节点向其他节点发送数据。根据图的稠密性选择合适的机制可以大幅提高效率。
-
优秀的开放性与兼容性
- 自定义算法支持PIE与Pregel计算模型:允许开发者根据自己的需求编写自定义算法,并且可以选择基于PIE或Pregel模型来执行这些算法。
- 支持基于GPU的图计算:GPU(图形处理单元)具有强大地并行处理能力,适合执行大规模图计算任务。支持GPU意味着可以进一步加速图计算的性能。
算法支持
离线图计算算法支持情况请参考算法列表。
ArcGraph 图计算架构
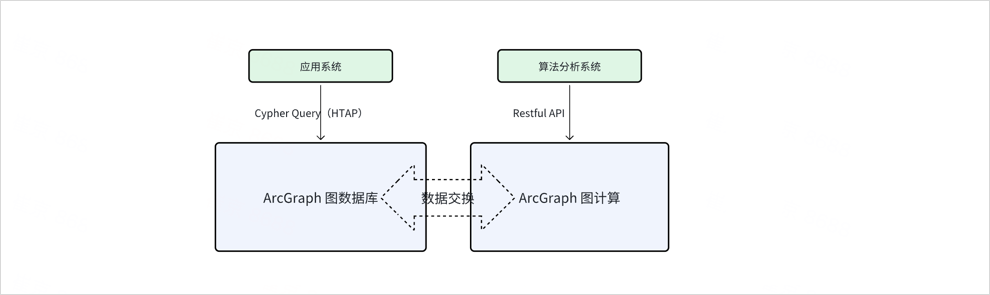
ArcGraph HTAP 架构
HTAP(Hybrid Transactional and Analytical Processing,混合事务和分析处理)是一种数据库架构,它可以同时处理 OLTP(Online Transaction Processing,在线事务处理)和 OLAP(Online Analytical Processing,在线分析处理)的请求。 HTAP 能够实时同步数据且可以通过查询语句生成数据并直接进行图计算,时效性较强。所以,HTAP 在图计算方面具有更高的灵活性和可扩展性,且简化了整体技术架构,减少维护的复杂性,满足了各种不同实际应用场景的需求。
ArcGraph HTAP 的整体架构由两个独立的集群组成: TP 集群和 AP 集群。这些集群可根据实际情况进行独立扩展和缩容,以实现灵活的资源管理和高可用性。在部署方面,HTAP Graph 支持根据实际情况单独部署和扩缩容,同时保持功能应用之间的联动性。这种架构提供了高度的灵活性和可扩展性,使得用户可以更加方便地使用 HTAP Graph 进行事务和分析处理。 HTAP Graph 整体架构图如下。
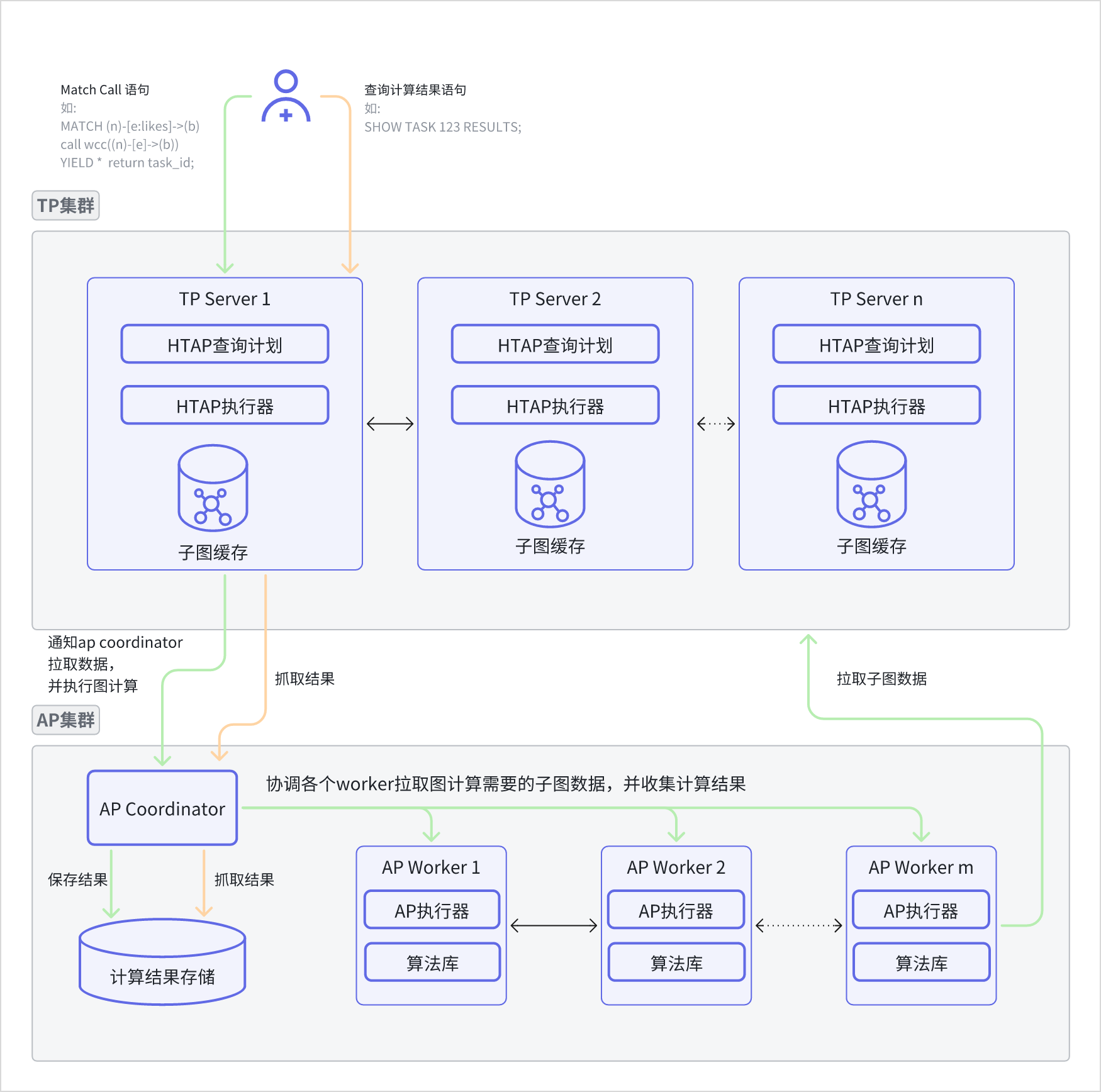
基本�概念
- TP 集群
由一个或多个 TP Server (即 TP 服务器)组成,主要负责处理事务性读写操作。每个 TP 服务器中,与 HTAP 工作密切相关的组件包括:- HTAP 查询计划,该组件用于解析用户的 HTAP 请求,并将其编译成执行计划。
- HTAP 执行器,该组件负责查询图的计算所需的数据,形成子图。
- 子图缓存,该组件负责缓存 HTAP 执行器的查询结果,等待 AP 工作节点来获取。目前支持内存(memory)和 TiKV 两种模式,具体模式由 TP 服务器的配置决定。
- AP 集群
主要用于执行大规模数据图计算任务,其中与 HTAP 工作密切相关的组件包括:- AP Coordinator,即 AP 协调器,负责接收 TP 服务器的 AP 请求,并协调各个 AP 工作节点来获取子图数据,执行算法。同时,协调器也负责协调 AP 工作节点来获取结果数据。
- AP Worker,由 AP 执行器和算法库组成,主要负责获取数据、执行 AP 算法,并将计算结果保存在计算结果存储中。
- 计算结果存储,负责保存图计算的结果,通常使用 MinIO 等存储系统。
基本流程
当用户发起 HTAP 语句时流程如下:
- 首先,用户通过客户端或驱动程序将语句文本发送到 TP 服务器。
- TP 服务器接收到语句文本后,解析并生成执行计划,生成唯一的查询 ID(task id)。
- TP 服务器开始执行查询操作。
查询结果将被存储为一个子图,并根据 TP 服务器的配置情况�,选择存储在内存、TiKV 或其他存储系统中。 - TP 服务器通知 AP 协调器需要执行的算法,以及数据存储的位置。
- TP 计算节点将查询 ID 返回给客户端,语句执行结束。
- AP 协调器根据接收到的请求,通知各个 AP 工作节点拉取输入数据。
- AP 工作节点从 TP 的子图缓存中拉取数据。
数据拉取完成后,图计算算法将被执行,执行结果将被保存至计算结果存储中。
当用户发起 HTAP 结果查询语句时,流程如下:
- 查询图计算结果的语句被发送至 TP 的计算节点。
- TP 计算节点解析语句并向 AP 协调器请求结果数据。
- 协调器根据任务 ID 从结果存储中获取数据,并将其返回。
- TP 计算节点将返回的结果传递给客户端。
说明:
只有一个查询 ID 时,通常无法直接查看图计算的结果,可以发起一条以查询 ID 为参数的查询结果语句,获取相应的结果数据。
HTAP Query 语法
前提条件
进行 HTAP 查询前请确认已部署 AP 并获取相关权限。
目前,用户只要具备执行 MATCH 权限,便可通过执行 MATCH CALL 语句来调用图计算功能。获取相关权限的方法详情请参见 权限 章节。
语法
图计算相关的 Cypher 语句采用 MATCH .. CALL 的形式组成。
-
执行图计算任务
语法
MATCH <pattern_part> [WHERE <expression>] CALL <algo_name> '(' <algo_params> ')'
[WITH HINT(SAMPLING)]
YIELD task_id
RETURN task_id;
algo_name ::= <Ident>
algo_params ::= <expression> [',' <expression>]参数说明
参数 说明 <algo_name>算法名,如 pagerank。<algo_params>参数,多个参数间以英文逗号分隔。 详细说明
MATCH部分是一个完整的只读的MATCH子句,用于查询参与图计算的相关点和边。CALL子句用于调用图算法。CALL子句后需要指定具体的算法名称<algo_name>和该算法需要的参数<params>,具体支持的算法请参见 算法列表 章节。WITH HINT(SAMPLING)可选配置,指定交给图计算的MATCH结果不超过1000条。没有该hint时, 对MATCH结果不做限制。YIELD子句用于返回CALL子句产出的结果。目前MATCH CALL只产出task_id。RETURN子句用于指定查询的返回结果。目前RETURN返回的是YIELD子句中返回的task_id,并作为结果返回给客户端。<Ident>、<expression>、<pattern_part>等语法详情请参见 DML(增|删|改) 章节。
-
获取图计算结果信息
语法
SHOW TASK <task_id>
RESULTS [LIMIT <limit>] [SKIP <skip>];
<task_id> ::= int64
<limit> ::= int32
<skip> ::= int32参数说明
参数 说明 <task_id>任务 ID。 <limit>(可选)返回结果的最大行数。请根据实际情况设置参数,则默认情况下只显示最多 5000 行。 <skip>(可选)跳过行数,若未设置参数,则默认情况下不跳过行。 详细说明
SHOW TASK子句用于显示查询的详细信息。RESULTS子句用于显示查询的结果。LIMIT子句用于限制返回结果的最大行数。查询结果将按照指定的限制行数返回,如果查询结果不足限制行数,则返回所有结果。SKIP子句用于指定结果的开始获取行数。后面跟着一个数字,表示结果中从第 n+1 行开始获取。
应用示例
通过 TP 入口执行图计算以及查询计算结果请参考以下步骤执行,此处以 LPA(Label Propagation Algorithm,标签传播算法)算法为例介绍。 若需要通过 Java SDK 应用 HTAP,示例方法请参见 ArcGraph Java SDK 章节。
-
执行 LPA 算法,发起图计算。
MATCH (n:person)-[e:knows]->(b:person)
call lpa((n)-[e]->(b), 3)
YIELD task_id
RETURN task_id; -
根据返回结果,获取任务 ID。
返回结果示例 1:
AP 顺利开始执行,返回task_id。+---------------------+
| task_id |
+=====================+
| 7107968001563041787 |
+---------------------+返回结果示例 2:
当前有 AP 任务正在执行,返回如下失败信息。请在当前任务结束后,再次发起执行请求,以获取正确的任务号。+----------------------------------------------------------------------------------------------------+
| error |
+====================================================================================================+
| Code: 8006, AP_ANALYTICAL_ENGINE_INTERNAL_ERROR: another task 7107968001563041787 already started. |
+----------------------------------------------------------------------------------------------------+返回结果示例 3:
AP 服务器连接异常,返回如下错误信息。请确认已部署 AP 并检查 AP 连接情况,如有需要可联系 我们 获取帮助。+-------------------------------------------------------------+
| error |
+=============================================================+
| Code: 8004, AP_NETWORK_ERROR: Fail to connect to AP server. |
+-------------------------------------------------------------+ -
通过任务 ID,执行下列命令,获取图计算结果信息。
SHOW TASK 7107968001563041787
RESULTS LIMIT 10;
RESTful API
自 ArcGraph 图数据库 v2.1.2 版本起,ArcGraph OLAP 引擎提供了一套完整的 RESTful API,允许用户通过 HTTP 请求与 ArcGraph OLAP 引擎进行交互,如提交图计算任务、查�询任务状态以及获取任务结果等。
URL 与方法
- URL:
http://localhost:8000/graph-computing/ - 方法:POST
请求头(Headers)
为确保 API 调用的顺利进行,需要在请求命令中包含必要的 HTTP 请求头信息。请求头参数说明如下:
| 参数 | 说明 | 是否可选 |
|---|---|---|
Accept | 用于指定客户端期望从服务器获取的数据格式,默认为 application/json。 | 否 |
Content-Type | 用于指定客户端发送给服务器的数据格式,默认为 application/json。 | 否 |
请求体(Request Body)
请求体是一个 JSON 对象,它包含了执行图计算算法所需的参数和配置。请求体参数说明如下:
| 参数 | 说明 | 是否可选 |
|---|---|---|
algorithmName | 算法英文名称,用于指定要执行的算法。 | 否 |
graphName | ArcGraph 图数据库中的图名称。 | 否 |
dataSetName | 图数据集名称,默认与 graphName 相同。 | 是 |
taskId | 任务的唯一标识符,它是一个由用户自定义的字符串(如果未配置,则系统会计算一个 uuid)。 | 是 |
dataSetSchema | 图的 Schema 信息,用于从 ArcGraph 图数据库中导出数据。它包括点类型(vertexTypes)和边类型(edgeTypes)的详细信息,需与 ArcGraph 图数据库中的图 Schema 匹配。
| 是 |
subGraph | 指定执行算法的子图结构,其格式与 dataSetSchema 相同。 | 否 |
algorithmParams | 算法执行时所需的特定参数。不同算法所需参数不同,请根据实际算法要求设置,算法参数详情请参见 请求参数(Algorithm Params) 章节。 | 否 |
示例
{
"algorithmName": "attribute_assortativity_coefficient",
"graphName": "LDBC_SNB",
"dataSetName": "LDBC_SNB",
"taskId": "attribute_assortativity_coefficient",
"dataSetSchema": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
],
"props": [],
"temporal": true
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": [
"weight"
]
}
]
},
"subGraph": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
],
"props": []
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": [
"weight"
]
}
]
},
"algorithmParams": {}
}
请求参数(Algorithm Params)
算法参数
支持的算法及算法执行时所需的算法参数如下:
| 算法/算法简介 | 参数名称 | 类型 | 是否可选 | 默认值 | 参数说明 |
|---|---|---|---|---|---|
| attribute_assortativity_coefficient 属性同配系数算法 | numeric | bool | No | true | |
| numeric_assortativity_coefficient 数值同配系数算法 | numeric | bool | No | true | |
| average_degree_connectivity 平均度连接性算法 | source | string | No | in+out | 仅适用于有向图。使用“入度”或“出度”表示源节点,允许的值包括 in(入度),out(出度),in+out(入度 + 出度) |
target | string | No | in+out | 仅适用于有向图。使用“入度”或“出度”表示目标节点,允许的�值包括 in(入度),out(出度),in+out(入度 + 出度) | |
| average_shortest_path_length 平均最短路径长度算法 | 无 | ||||
| betweenness_centrality 介数中心性算法 | normalized | bool | Yes | true | 是否归一化 |
endpoints | bool | Yes | false | 是否包含 endpoints | |
| edge_betweenness_centrality 边介数中心性算法 | normalized | bool | Yes | true | 是否归一化 |
| bfs 广度优先搜索算法 | src | int/string | No | 0 | 广度优先搜索的源顶点 |
k | int | Yes | 0 | k | |
| bfs_generic 广义广度优先搜索算法 | src | int/string | No | None | 广度优先搜索的源顶点 |
limit | int | Yes | 10 | 深度限制 | |
format | string | Yes | predecessors | 值为 successors 或者 predecessors | |
| closeness_centrality 紧密中心性算法 | wf_improved | bool | Yes | true | 是否采用 Wasserman and Faust 公式改进 |
| avg_clustering 平均聚类系数算法 | degree_threshold | int | Yes | 10000000000 | 度数限制 |
| clustering 聚类系数算法 | degree_threshold | int | No | 10000000000 | |
| degree_assortativity_coefficient 度同配系数算法 | x | string | Yes | None | 目标节点的度类型,可用选项有 in 或者 out |
y | string | Yes | None | 源节点类型,可用选项有 in 或者 out | |
weighted | bool | No | false | ||
| degree_centrality 度中心性算法 | centrality_type | string | Yes | None | 中心度类型,可用选项有 in,out 或者 both |
| dfs 深度优先搜索算法 | src | int/string | Yes | None | 深度优先搜索的源顶点 |
| edge_boundary 边界边算法 | nbunch1 | string | Yes | None | 顶点列表 1 |
nbunch2 | string | Yes | None | 顶点列表 2 | |
| eigenvector_centrality 特征向量中心度算法 | tolerance | float | Yes | 1e-06 | 收敛偏差 |
max_round | int | Yes | 100 | 最大迭代轮数 | |
| hits 链接分析算法 | tolerance | float | Yes | 0.01 | 收敛偏差 |
max_round | int | Yes | 10 | 最大迭代轮数 | |
normalized | bool | Yes | true | 是否将结果归一化为 0-1。默认为 true | |
| is_simple_path 简单路径算法 | nodes | string | Yes | None | 一个包含一个或多个图 G 中节点的列表 |
| all_simple_paths 全简单路径算法 | src | string | No | None | 起点 |
nodes | string | No | None | 目标点数据列表 | |
limit | int | No | 100000000 | 数量限制 | |
| k_core k 核算法 | k | int | No | 0 | k_core 的阶数 |
| k_shell K-Shell 算法 | k | int | No | 0 | k_shell 的阶数 |
| katz_centrality Katz 中心性算法 | alpha | float | Yes | 0.1 | 衰减因子 |
beta | float | Yes | 1.0 | 分配给直接邻居的权重 | |
tolerance | float | Yes | 1e-06 | 收敛偏差 | |
max_round | int | Yes | 100 | 最大迭代轮数 | |
normalized | bool | Yes | true | 是否将结果归一化为 0-1。默认为 true | |
degree_threshold | int | Yes | 1e9 | 是否将结果归一化为 0-1。默认为 true | |
| louvain 鲁汶算法 | min_progress | int | Yes | 1000 | 内层循环数 |
progress_tries | int | Yes | 1 | 外层循环数 | |
| girvan_newman Girvan-Newman 社交网络算法 | community_num | int | Yes | 10 | 社区数量 |
| cdlp 标签传播算法(LPA) | max_round | int | Yes | 10 | 最大迭代轮数 |
| slpa SLPA 社交网络分析算法 | max_round | int | Yes | 10 | 最大迭代轮数 |
r | float | Yes | 0.3 | ||
| wcdlp 加权标签传播算法 | max_round | int | Yes | 10 | 最大迭代轮数 |
| lpa_u2i lpa_u2i 社交网络分析算法 | max_round | int | Yes | 10 | 最大迭代轮数 |
| node_boundary 节点边界算法 | nbunch1 | string | Yes | None | 顶点列表 1 |
nbunch2 | string | Yes | None | 顶点列表 2 | |
| pagerank_nx pagerank_nx 算法 | alpha | float | Yes | 0.85 | 计算因子 |
max_iter | int | Yes | 10 | 算法迭代次数 | |
tol | float | No | 0.000001 | ||
| pagerank 网页排名算法 | delta | float | Yes | 0.85 | 计算因子 |
max_round | int | Yes | 10 | 算法迭代次数 | |
tol | float | No | 0.000001 | ||
| wpagerank 改进版的 PageRank 算法 | alpha | float | Yes | 0.85 | 计算因子 |
max_iter | int | Yes | 10 | 算法迭代次数 | |
tol | float | Yes | 1e-6 | 计算因子 | |
| ppagerank 改进版的 PageRank 算法 | src | int/string | Yes | None | 源点 id |
alpha | float | Yes | 0.85 | 计算因子 | |
max_iter | int | Yes | 10 | 算法最大迭代轮数 | |
tol | float | No | 1e-6 | ||
| sybil_rank Sybil 攻击的社交网络算法 | sources | string | Yes | None | 源点 id 列表 |
total_trust | float | Yes | 0.85 | 计算因子 | |
max_iter | int | Yes | 10 | �算法最大迭代轮数,推荐设置为 log(|V|) | |
| trust_rank 信任排名算法 | seeds | string | No | None | 信任节点列表 |
alpha | float | Yes | 0.85 | 阻尼因子 | |
max_iter | int | Yes | 10 | 算法最大迭代轮数,推荐设置为 log(|V|) | |
tol | float | Yes | 1e-6 | ||
| sssp 单源最短路径算法 | src | int/string | Yes | None | 源顶点 |
| shortest_path 最短路径算法 | src | int/string | No | None | 源顶点 |
target | int/string | No | None | 目标顶点 | |
weight | string | Yes | None | 边类型属性名称, 仅支持int32,int64,float,double类型的属性选 | |
rank | string | Yes | None | ||
| all_shortest_path 全最短路径算法 | src | int/string | No | None | 源顶点 |
target | int/string | No | None | 目标顶点 | |
k | int | Yes | None | 最大跳数 | |
directed | int | Yes | None | 方向,允许的选项有 0(in),1(out),2(both) | |
weight | string | Yes | None | 边类型属性名称, 仅支持int32,int64,float,double类型的属性选 | |
rank | string | Yes | None | ||
| ksssp k 步最短路径算法 | src | int/string | Yes | None | 源顶点 |
k | int | Yes | 1 | hop 数量 | |
| mssp 多源最短路径算法 | sources | string | Yes | None | 源点 id 列表 |
| sssp_has_path 路径存在判断算法 | src | int/string | No | None | 源顶点 |
dst | int/string | No | None | 目标顶点 | |
| sssp_all_pairs_length 节点对最短路径算法 | 无 | ||||
| diameter 直径估计算法 | sample | int | Yes | None | 采样数 |
| transitivity 传递性算法 | 无 | ||||
| triangles 三角计数算法 | |||||
| voterank 投票排名算法 | num_of_nodes | int | Yes | None | 要提取的排名节点数量。默认为所有节点 |
| random_walk 随机游走算法 | nodes | string | Yes | None | 源点 id 列表 |
length | int | No | None | 随机游走长度 | |
| vertex_similarity 节点相似性算法 | nodes1 | string | Yes | None | 顶点 id 列表 1 |
nodes2 | string | Yes | None | 顶点 id 列表 2 | |
metric | string | Yes | common | 度量方法,支持 common 和 jaccard | |
| vertex_similarity_ss 节点相似性 ss 算法 | src | int/string | Yes | None | 顶点 id 列表 1 |
k | int | Yes | None | 返回 top 数 | |
metric | string | Yes | common | 度量方法,��支持 common 和 jaccard | |
| wcc_projected 弱连通分量算法 | 无 | ||||
| scc 强连通分量算法 | |||||
| number_connected_components 弱连通分量数算法 | |||||
| graph_matching 子图匹配算法 GAE 版本 | limit | int | Yes | 10 | |
vertices | string | No | |||
edges | string | No | |||
rank | string | Yes | |||
| graph_matching_query 子图匹配算法 gremlin 版本 | pattern | string | No | ||
limit | int | Yes | 10 | ||
rank | string | Yes | |||
| cycle_detection 环路检测算法 | limit | int | No | None | 结果循环限制 |
khop | int | No | None | k-hop 数量 | |
rank | string | Yes | _ts | ||
| sequential_cycle_detection 时序环路发现算法 | nodes_json | string | Yes | ||
node_attribute | string | Yes | |||
khop | string | Yes | 2,6 | ||
first_edge_time_range | string | Yes | 0,0 | ||
attribute | string | Yes | 边属性 | ||
limit | int | Yes | |||
bfs_level | int | Yes | 3 | ||
| cycle_detection_filter 带过滤的环�路检测算法 | src | int/string | Yes | None | 源顶点的 ID |
vertex_type | string | Yes | None | 点类型名称 | |
edge_prop | string | Yes | None | 用于过滤的边属性名称 | |
khop | int | No | None | k-hop 数量 | |
prop_threshold | float | Yes | None | 边属性过滤的阈值 | |
rank | string | Yes | None | ||
| all_path_search 全路径搜索算法 | nodes1 | string | Yes | None | 顶点 id 列表 1 |
nodes2 | string | Yes | None | 顶点 id 列表 2 | |
k | int | Yes | None | k-hop 数量 | |
rank | string | Yes | _ts | ||
| ego_net 本体网络算法 | src | int/string | Yes | None | 源点 id |
k | int | Yes | 1 | k-hop 数量 | |
rank | string | Yes | _ts | ||
| multi_source_khop 查找多个源节点与目标节点之间的 k-hop 路径的一种算法 | src_ids | string | No | None | 源点 id 列表 |
v_type | string | Yes | None | 点类型名称 | |
e_type | string | Yes | None | 边类型名称 | |
dir | int | Yes | None | 方向, 允许的选项有0(in),1(out),2(both) | |
khop1 | int | Yes | None | k-hop 数量下限 | |
khop2 | int | Yes | None | k-hop 数量上限 | |
count | bool | Yes | false | 是否只统计数量,不返回具体的点 | |
| node2vec node2vec 算法 | dim | int | Yes | 128 | 图嵌入的维度 |
p | float | Yes | 1 | 游走时用到的概率 p | |
q | float | Yes | 1 | 游走时用到的概率 q | |
walk_length | int | Yes | 20 | 游走路径长度 | |
walks_per_node | int | Yes | 10 | 每个节点游走次数 | |
epoch | int | Yes | 10 | 训练epoch数 | |
在有向图中,点(顶点)的入度是指进入该点(顶点)的边的条数;出度是指从该点(顶点)出发的边的条数。
点/边属性支持
各算法对点属性和边属性的支持情况如下:
| 算法 | 是否接受点属性 | 是否接受边属性 |
|---|---|---|
| attribute_assortativity_coefficient、numeric_assortativity_coefficient | True | False |
| average_degree_connectivity、average_shortest_path_length、degree_assortativity_coefficient、eigenvector_centrality、katz_centrality、louvain、wcdlp、wpagerank、sssp、shortest_path、all_shortest_path、ksssp、mssp、sssp_all_pairs_length、diameter | False | True |
| betweenness_centrality、edge_betweenness_centrality、bfs、bfs_generic、closeness_centrality、avg_clustering、clustering、degree_centrality、dfs、edge_boundary、hits、is_simple_path、all_simple_paths、k_core、k_shell、girvan_newman、lpa、slpa、lpa_u2i、node_boundary、pagerank_nx、pagerank、ppagerank、sybil_rank、trust_rank、sssp_has_path、transitivity、triangles、voterank、random_walk、vertex_similarity、vertex_similarity_ss、wcc、scc、number_connected_components、graph_matching、graph_matching_query、cycle_detection、sequential_cycle_detection、cycle_detection_filter、all_path_search、ego_net、multi_source_khop、node2vec | False | False |
其他参数
在发送请求时,可以通过在请求 URL 的末尾附加特定的查询参数来调整行为。参数详情如下:
| 参数 | 说明 | 是否可选 |
|---|---|---|
use_cache | 用于指定是否启用图缓存机制。当此参数设置为 true 时,算法首次执行将自动缓存图数据至内存中,以确保后续执行相同算法时能够直接从缓存中读取图数据,避免重复加载,有效提升图计算性能。 | 是 |
reload | 用于指定是否强制重新加载图。 | 是 |
示例
'http://localhost:8000/graph-computing/algos/attribute_assortativity_coefficient?use_cache=true&reload=false'
响应
成功响应(200)
提交请求成功后,服务器将返回一个 JSON 格式的响应,如下所示:
-
Media Type:
application/json -
Example Value:
{
"code": 200,
"msg": "Success",
"data": "string"
}
验证错误(422)
如果请求体中的参数不符合要求,服务器将返回包含错误信息的 JSON 响应,如下所示:
-
Media Type:
application/json -
Example Value:
{
"detail": [
{
"loc": [
"string",
0
],
"msg": "string",
"type": "string"
}
]
}
RESTful API 应用
前提条件
在使用 RESTful API 前,请确保您已经成功部署了单机版或敏捷版 ArcGraph 图数据库中的 ArcGraph OLAP 引擎。
发起图计算任务
本章节以 attribute_assortativity_coefficient 算法为例,介绍如何发起图计算任务。
请求 URL: http://localhost:8000/graph-computing/
请求方式: POST
curl 示例:
curl -X 'POST' 'http://localhost:8000/graph-computing/'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"algorithmName": "attribute_assortativity_coefficient",
"graphName": "LDBC_SNB",
"dataSetName": "LDBC_SNB",
"taskId": "attribute_assortativity_coefficient",
"dataSetSchema": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
],
"props": [],
"temporal": true
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": ["weight"]
}
]
},
"subGraph": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
],
"props": []
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": ["weight"]
}
]
},
"algorithmParams": {}
}'
返回结果示例如下:
{
"code": 200,
"msg": "Success",
"data": "string"
}
查询任务状态
在提交图计算任务后,可以发送 GET 请求到相应的任务状态查询接口来查询任务的状态,了解任务的执行进度。
请求 URL: http://localhost:8000/graph-computing/
请求方式: GET
curl 示例:
curl -X 'GET' \
'http://localhost:8000/graph-computing/status?task_id=attribute_assortativity_coefficient&with_log=false' \
-H 'accept: application/json'
返回结果示例如下:
{
"code": 200,
"msg": "success",
"data": {
"taskId": "attribute_assortativity_coefficient",
"graphId": 0,
"algorithm": "attribute_assortativity_coefficient",
"code": "0",
"message": "",
"status": "finished",
"subStatus": "",
"resultSize": 1,
"resultStorageType": "local",
"resultStorageFormat": "csv",
"resultStorageProperties": "",
"log": "",
"errors": []
}
}
查询图计算结果
在提交图计算任务后,可以发送 GET 请求到相应的结果查询接口获取图计算的结果。
请求 URL: http://localhost:8000/graph-computing/
请求方式: GET
curl 示例:
curl -X 'GET' \
'http://localhost:8000/graph-computing/result?task_id=attribute_assortativity_coefficient&with_log=true&limit=100&skip=0' \
-H 'accept: application/json'
返回结果示例如下:
{
"code": 200,
"msg": "success",
"data": {
"status": "finished",
"log": "",
"errors": [],
"result": {
"header": [
"0"
],
"data": [
[
"-0.010865380609647247"
]
]
}
}
}
图模式匹配
在图数据库执行图模式匹配操作时,为了从海量数据中精确提取符合特定条件的数据,通常需要对图中的点和边进行属性过滤。自 ArcGraph 图数据库 v2.1.2 版本起,ArcGraph OLAP 引擎新增了对图模式匹配的支持,具体包括单点/边属性过滤和跨点/边属性过滤两种过滤机制。
单点/边属性过滤
执行单点/边属性过滤操作时,用户可选择在 vertexTypes(点类型)和 edgeTypes(边类型)的每个元素上添加 filters 属性(可选),以实现对点和边属性的精准过滤。filters 属性定义为数组类型,数组中的每个元素均为一个 filter 对象。这些 filter 对象之间遵循逻辑与(AND)关系,即所有列出的过滤条件须同时满足,才能成功匹配到目标点或边,从而确保查询结果的准确性和高效执行。
filter 包含以下三个属性:
field:字符串类型,用于指定要过滤的属性名。它支持对_oid、_ts及普通属性执行过滤操作,但不支持对边的_src_id和_dst_id属性进行过滤。op:字符串类型,指定比较运算符。目前支持的运算符有eq(等于)、neq(不等于)、gt(大于)、gte(大于等于)、lt(小于)、lte(小于等于)、within(在指定范围内)value:字��符串类型,指定与属性进行比较的值。如果比较的值是字符串,则需要用\"符号包裹,如"\"abc\""。
- 日期类型属性无法直接用字符串匹配。若需采用字符串匹配方式查询日期型字段,则要求该字段在 CSV 导入时未被设定为 TIMESTAMP 类型。
- 在执行边属性过滤操作时,不支持对
_src_id和_dst_id属性进行过滤。如果需要对这两个属性进行过滤,建议调整策略,改为在边的起始点和目标点上设置相应的过滤条件来实现。
示例 1
filters 的结构示例如下:
"filters":[{"field":"firstName", "op":"eq", "value":"\"David\""}]
示例 2
完整的请求示例如下:
{
"algorithmName": "graph_matching_query",
"graphName": "LDBC_SNB_REGRESSION",
"dataSetName": "LDBC_SNB_REGRESSION",
"taskId": "01_without_filter1201",
"dataSetSchema": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
],
"props": ["_ts"],
"temporal": true
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": ["weight"]
}
]
},
"subGraph": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
],
"props": ["_ts"]
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": ["weight"]
}
]
},
"algorithmParams": {
"limit": 1000,
"rank": "",
"pattern": {
"edgeTypes": [
{
"patternSource": "v1",
"patternTarget": "v2",
"edgeTypeName": "knows",
"filters":[{"field":"_ts", "op":"gt", "value":"0.5"},{"field":"_ts", "op":"lt", "value":"0.7"}]
},
{
"patternSource": "v2",
"patternTarget": "v3",
"edgeTypeName": "knows"
}
],
"vertexTypes": [
{
"patternId": "v1",
"vertexTypeName": "person",
"filters":[{"field":"weight", "op":"gt", "value":"0.5"},{"field":"weight", "op":"lt", "value":"0.7"}]
},
{
"patternId": "v2",
"vertexTypeName": "person"
},
{
"patternId": "v3",
"vertexTypeName": "person"
}
]
}
}
}
跨点/边属性过滤
ArcGraph 图数据库不仅支持单点/边属性过滤,还支持跨点/边属性过滤。用户只需在与 vertexTypes 和 edgeTypes 并列的位置处添加 filters 属性(可选),即可实现不同点和边之间的属性过滤。
filters 属性定义为数组类型,数组中的每个元素均为一个 filter 对象。这些 filter 对象之间遵循逻辑与(AND)关系,即所有列出的过滤条件须同时满足,才能成功匹配到目标点或边。
filter 包含以下关键属性,通过灵活配置这些属性,用户能够构建出复杂且精确的跨点/边属性过滤条件,以满足多样化的图模式匹配需求。
pattern1和pattern2:字符串类型,分别指定第一个和第二个过�滤的模式(pattern)名字。若过滤对象为点,则该名字为vertexTypes中元素的patternId属性值;若过滤对象为边,则该名字为edgeTypes中元素的位置索引(从 0 开始)。type1和type2:字符串类型,用于指明pattern1和pattern2分别代表的是点还是边。其中,“v”表示点,“e”表示边,不支持其他选项。field1和field2:字符串类型,分别指明pattern1和pattern2上需要比较的属性名。op:字符串类型,指定用于比较两个属性值的运算符。
- 日期类型属性无法直接用字符串匹配。若需采用字符串匹配方式查询日期型字段,则要求该字段在 CSV 导入时未被设定为 TIMESTAMP 类型。
- 在执行边属性过滤操作时,不支持对
_src_id和_dst_id属性进行过滤。如果需要对这两个属性进行过滤,建议调整策略,改为在边的起始点和目标点上设置相应的过滤条件来实现。
示例 1
filters 的结构示例如下:
"filters":[{
"pattern1": 0,
"type1":"e",
"pattern2": "1",
"type2":"e",
"op":"lt",
"field1":"_ts",
"field2":"_ts"
},{
"pattern1": "v1",
"type1":"v",
"pattern2": "v3",
"type2":"v",
"op":"lt",
"field1":"_oid",
"field2":"_oid"
}]
示例 2
完整的请求示例如下:
{
"algorithmName": "graph_matching_query",
"graphName": "LDBC_SNB_REGRESSION",
"dataSetName": "LDBC_SNB_REGRESSION",
"taskId": "graph_matching5",
"dataSetSchema": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
],
"props": [],
"temporal": true
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": []
}
]
},
"subGraph": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
],
"props": ["_ts"]
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": []
}
]
},
"algorithmParams": {
"limit": 10,
"rank": "",
"pattern": {
"edgeTypes": [
{
"patternSource": "v1",
"patternTarget": "v2",
"edgeTypeName": "knows"
},
{
"patternSource": "v2",
"patternTarget": "v3",
"edgeTypeName": "knows"
}
],
"vertexTypes": [
{
"patternId": "v1",
"vertexTypeName": "person",
"filters":[{"field":"_oid","op":"eq","value":"21990232555940"}]
},
{
"patternId": "v2",
"vertexTypeName": "person",
"filters":[{"field":"_oid","op":"eq","value":"26388279066936"}]
},
{
"patternId": "v3",
"vertexTypeName": "person"
}
],
"filters":[{
"pattern1": 0,
"type1":"e",
"pattern2": "1",
"type2":"e",
"op":"lt",
"field1":"_ts",
"field2":"_ts"
},{
"pattern1": "v1",
"type1":"v",
"pattern2": "v3",
"type2":"v",
"op":"lt",
"field1":"_oid",
"field2":"_oid"
}]
}
}
}